
L'internet pour les nuls (partie 1 sur N)
Cet article a été initialement publié sur le blog OCTO.
Pourquoi cette série d’articles ?
Cet article est le premier d’une série sur les protocoles réseaux contemporains.
- Partie 1: Historique et modélisation
- Partie 2: Ethernet
L’objectif de cette série est d’offrir une vision complète, cohérente et didactique des différents protocoles mis en œuvre lors d’une communication entre plusieurs machines, afin de donner une vue d’ensemble et démystifier un domaine qui est souvent mis de côté dans l’étude de l’informatique.
À travers plusieurs articles, nous aurons donc l’occasion d’abord d’avoir un état de l’art de la pile réseau telle qu’elle est rencontrée aujourd’hui et son évolution à travers ces trente dernières années, puis nous nous attarderons en détail sur les protocoles incontournables tels que ethernet, IP et TCP. Enfin, la série d’articles se conclura par des sujets divers comme les différents aspects de la sécurité, la virtualisation de composants réseau avec l’étude du NFV (Network Function Virtualization), ou encore les protocoles d’overlay tels que VXLAN ou GRE.
Parce qu’un chemin bien parcouru commence toujours par le premier pas, nous débuterons avec un premier article moins technique, présentant l’histoire rapide des différentes briques conceptuelles que nous aurons l’occasion de détailler par la suite.
Protocoles réseaux : une approche historique
Un temps que les moins de vingt ans…
Aujourd’hui, les protocoles réseau venant immédiatement à l’esprit sont des protocoles tels que IP, TCP, UDP, appartenant notamment à la pile TCP/IP, et créer un réseau local est devenu synonyme d’attribuer une adresse IP à chaque machine pour les faire communiquer en TCP ou en UDP. Pourtant, seulement quelques années plus tôt, d’autres suites de protocoles comme IPX/SPX de Novell se disputaient la place.
Un exemple particulièrement frappant est celui-ci : comme bon nombre de mes collègues, j’ai passé de nombreuses heures, plus jeune, à jouer à des jeux en réseau avec des amis d’école, et le jeu incontournable de l’époque était sans aucun doute Starcraft. Lors de sa sortie en 1998, le jeu ne proposait tout simplement pas la possibilité de faire un réseau local en TCP/IP, mais proposait IPX ! Il fallut attendre 2002 et le patch 1.09 pour enfin pouvoir faire un réseau local basé sur la stack IP. Comme quoi, ce n’est pas si loin que ça.
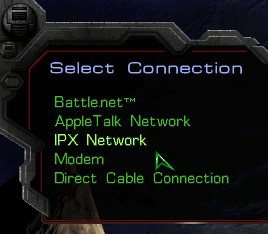
Starcraft lors de sa sortie, 1998
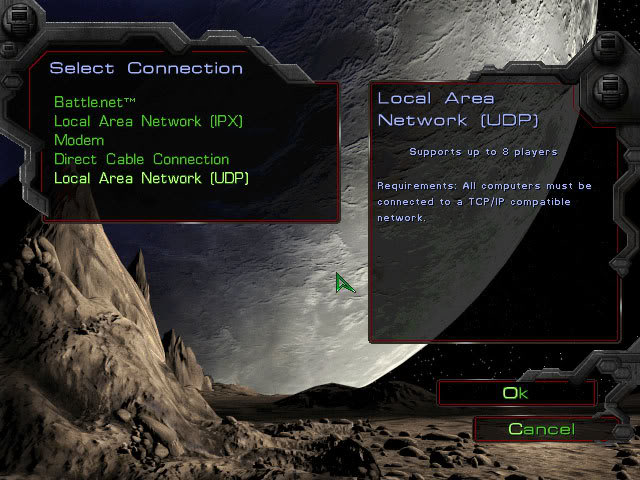
Starcraft après le patch 1.09, 2002
À l’origine des réseaux modernes : le packet switching
Le packet switching, ou « commutation par paquets », fut la grande
révolution théorique à l’origine des réseaux modernes, marquant une
différence fondamentale avec la commutation par circuit qui était alors
la seule manière d’établir une connexion. Pour comprendre ce qui
différencie ces deux concepts, il faut se poser la question suivante :
lors d’une communication entre deux appareils distants, quel « chemin »
prennent les paquets réseau, et comment ce chemin est-il déterminé ?
Dans le cas de la commutation par circuit, le chemin est établi en amont de la communication. Ce circuit peut être un circuit fixe utilisé dans tous les cas, ou bien créé au cas par cas lors d’une phase de négociation préalable à la communication en elle-même. Ainsi, tous les messages, aller ou retour, passent par ce circuit établi. De plus, la connexion étant dédiée, personne ne peut joindre l’un des deux interlocuteurs pendant la durée de la communication. Cette technologie, la plus ancienne, est associée aux réseaux téléphoniques où elle a d’abord fait son apparition en 1878, deux petites années après l’invention du téléphone en 1876.
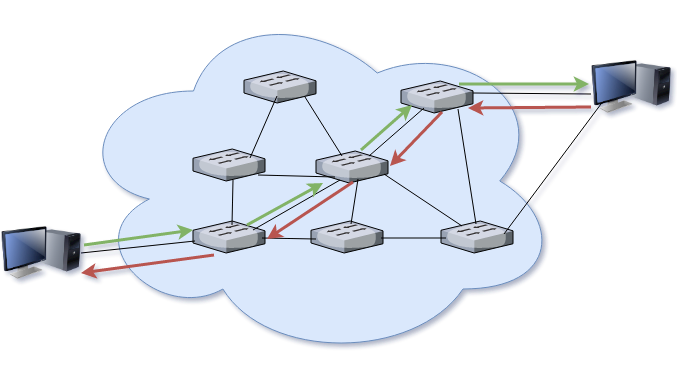
Commutation par circuit
Si ces circuits restent adaptés à la téléphonie, ils posaient un grand problème pour l’arrivée des ordinateurs : ce qui coûtait cher dans la commutation par circuit, c’était d’en créer un nouveau pour chaque commutation. Ce coût était cependant absorbé en imposant aux clients un prix minimal à chaque communication.
Mais les ordinateurs, communiquant par pics d’activité brefs, n’étaient pas du tout adaptés à cette technologie.
De plus, il était facile pour un intervenant malicieux d’interrompre une communication ou d’empêcher son établissement : il suffisait de casser un maillon quelconque de la chaîne, typiquement le point central. Vers le début des années 60, des travaux de recherche sont engagés indépendamment par deux chercheurs : Paul Baran de RAND et Leonard Kleinrock du MIT. Ces travaux mènent à la conception d’un système de commutation par paquets.
Contrairement à la commutation par circuit, la commutation par paquet ne demande pas l’établissement au préalable d’un chemin dédié à la communication. Le message est découpé en petites entités individuelles (les paquets), et chacun est commuté individuellement. Sur le chemin, chaque paquet peut être routé, combiné, fragmenté, pour l’amener à sa destination. Le destinataire a pour tâche de recomposer le message originel.
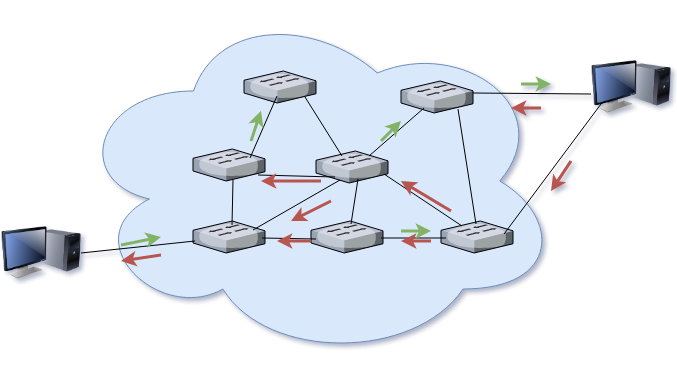
Commutation par paquet
Les avantages de cette technique sont considérables. Elle permet notamment d’offrir un support de communication partagé plutôt que dédié, et à une machine de communiquer avec plusieurs autres en même temps – leurs paquets respectifs étant mélangés et traités indépendamment.
Enfin, un argument non négligeable est celui de la sécurité : en retirant les points intermédiaires critiques de l’équation, un réseau à base de commutation de paquet permet de survivre à la disparition d’une partie des nœuds intermédiaires. C’est notamment cet aspect qui poussa l’agence américaine DARPA à développer le premier réseau basé sur la commutation de paquet, ARPANET.
Un premier réseau « packet switché »: ARPANET
Un mythe particulièrement tenace dans le folklore du réseau est que
l’objectif principal d’ARPANET était de construire un réseau capable de
survivre à une attaque nucléaire de la part de l’union soviétique. Nous
étions en pleine guerre froide, après tout. Bien que désormais démentie,
cette histoire illustre la vision militaire qui fut présente pendant les
vingts années d’existence de ce réseau.
Déployé en 1969, il fallut attendre 1972 pour l’envoi du premier courrier électronique, et la naissance du @ comme séparateur.
Durant ses vingts ans de vie, ARPANET fut le terreau fertile et le champ
de bataille sur lequel s’affrontèrent deux suites de protocoles basés
sur la commutation par paquets : OSI et TCP/IP.
OSI et TCP/IP, une bataille idéologique
Si de nombreux modèles ont coexisté pendant plusieurs années, il est commun de n’en retenir que deux : les modèles OSI et TCP/IP qui se sont farouchement affrontés pendant une quinzaine d’années. Si le gagnant sans conteste aujourd’hui est TCP/IP, le modèle OSI reste très utile dans un cadre théorique et pédagogique, ce qui explique sa présence dans presque tous les cours de réseau offerts.
S’attarder sur l’histoire complexe et sanglante de la lutte entre ces deux groupes mériterait un livre entier, de l’ancêtre commun qu’était l’International Networking Working Group et sa scission en deux groupes rivaux, aux luttes politiques entre différentes agences gouvernementales américaines, en passant par la naissance « officielle » de l’Internet en Janvier 1983. Il serait d’autant plus dommage de faire ce travail sachant que ce livre existe déjà1, qu’il se trouve dans la bibliographie en fin d’article, et que sa lecture est chaudement recommandée !
L’analyse historique des raisons ayant amené au succès de l’un face à l’autre est d’autant plus compliquée que, les faits ne parlant jamais d’eux-mêmes, elle est l’enjeu d’une lutte idéologique, politique et économique. Ainsi, on trouve facilement de nombreuses lectures transformant cette histoire en une fable hayekienne de l’échec inévitable d’une organisation bureaucratique « top down », auxquelles s’opposent des interprétations démontrant qu’à l’inverse, c’est l’implication gouvernementale du département de la défense américain qui a permis à l’autre camp de triompher. Un excellent article de l’IEEE Spectrum2 sur le sujet est disponible dans la bibliographie.
De la même manière, en tant que consultant OCTO, entreprise marquée par son attachement profond aux méthodologies agiles et leurs modèles d’organisation, il est tentant de surtout voir dans la défaite du modèle OSI celle d’une modélisation théorique trop lourde et contraignante, au contraste des itérations rapides de ce qui fut d’abord une implémentation avant d’être un standard dans le cas de TCP/IP.
Aussi, nous nous contenterons de la simplification suivante : OSI et TCP/IP se sont battus, TCP/IP a gagné et est le modèle de référence aujourd’hui. Néanmoins, OSI reste un excellent modèle théorique pour comprendre les différentes problématiques liés au réseau, et les couches d’abstraction qui y sont liés. En conséquence, le jargon contemporain expose souvent un modèle hybride, reprenant les meilleurs éléments des deux modèles.
Dans les sections suivantes, nous détaillerons le fonctionnement de ces deux modèles, avant de présenter le modèle hybride utilisé actuellement.
Le modèle OSI
Le modèle OSI est la fusion de deux groupes de travail indépendants, mais qui avaient le même objectif : établir une fois pour toute un standard unique sur l’architecture des systèmes réseau. Les produits de ces deux groupes, l’International Organization for Standardization (ISO), et le Comité Consultatif International Télégraphique (CCIT), furent fusionnés en 1983 pour créer un nouveau standard, le fameux Basic Reference Model for Open Systems Interconnection, ou simplement le modèle OSI.
Assez ironiquement, la plupart des gens pensent aujourd’hui que le modèle OSI n’avait dès le début qu’une simple vocation pédagogique, mais cette fondation se voulait être la base d’une suite de protocoles adoptés par le monde entier, la fameuse OSI Protocol Suite. Comme vous avez pu le comprendre, cette suite a été, modulo quelques protocoles survivants, complètement balayée par l’histoire et par TCP/IP ; et ne seront donc pas abordés dans cet article. Nous n’étudierons donc que le modèle de référence, dans un cadre purement théorique.
Trêve de perspectives historiques, il est grand temps de nous attaquer au modèle. La première leçon à retenir dans cette étude est que le modèle est divisé en couches, au nombre de 7. Chaque couche représente un domaine fonctionnel, une sous-problématique au sein du problème général de la communication en réseau, et ne peut communiquer qu’avec les couches immédiatement au dessus et en dessous d’elle.
Un autre aspect essentiel du modèle est le concept d’encapsulation : lors de l’émission d’un message sur le réseau, les couches sont parcourues du haut vers le bas, et chaque couche ajoute un en-tête au contenu de la couche supérieure, en-tête qui sera lui-même considéré comme un payload par la couche inférieure, et qui y ajoutera son propre en-tête.
À la réception, c’est le trajet inverse qui est fait : les couches sont parcourues du bas vers le haut, dépilant au fur et à mesure les différents en-têtes pour les traiter. Les couches du bas peuvent également être traitées par des appareils intermédiaires comme des switches ou des routeurs, qui ne regardent que celles-ci.
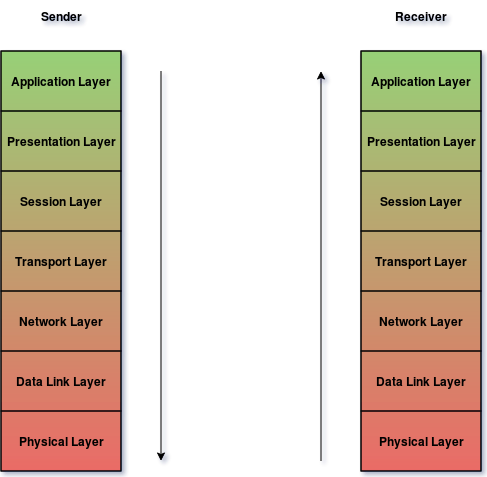
Modèle OSI
Sans plus attendre, regardons les différentes responsabilités des couches, en partant de la plus basse. Le contenu de ces en-têtes n’est pour l’instant pas spécifié, car c’est le rôle des protocoles en eux-mêmes : le modèle OSI indique simplement leur rôle et l’objectif de chacun de ces protocoles.
Couche 1 : Physique
La couche 1 est la couche physique, et elle est la seule qui s’occupe du transfert effectif de donnée à travers le réseau. On y retrouve notamment la définition des spécifications matérielles pour les câbles et les cartes, ainsi que l’encodage du signal physique pour un transfert efficace.
Les appareils fonctionnant sur cette couche, comme les répéteurs, n’ont absolument aucune connaissance du contenu des messages transmis : ils se contentent de manipuler des bits d’entrée et d’en envoyer en sortie.
Couche 2 : Liaison de données (Data Link)
Les définitions proposées pour cette couche sont parfois un peu vagues, aussi je me permettrai d’abord la simplification suivante: la couche de liaison de donnée est responsable de tout ce qui est nécessaire pour faire fonctionner un réseau local (LAN), et toutes les technologies de réseau local (Ethernet, Token Ring, FDDI…) se situent sur cette couche.
Plus spécifiquement, on découpe généralement la couche 2 en deux sous-couches : Logical Link Control (LLC) et Media Access Control (MAC).
Le MAC est la sous-couche du dessous, et permet comme son nom l’indique de contrôler l’accès au médium physique sous-jacent : si tous les appareils envoient leurs signaux en même temps sur un même câble, tout le trafic sera corrompu et aucun message ne pourra transiter. Il faut donc développer des protocoles régulant le tour de parole et de quel manière les différents appareils obtiennent la permission de s’exprimer sur le médium. Ces protocoles existent dans la sous-couche MAC.
Le LLC est la sous-couche du dessus, et sert principalement de multiplexeur, permettant de faire cohabiter plusieurs protocoles réseaux des couches supérieures sur le même support physique, et donc le même protocole MAC. Ainsi, un segment L2 donné (par exemple ethernet, wifi, bluetooth…) serait capable de supporter simultanément des paquets de différents protocoles L3 (comme IP, IPX, appletalk…).
On trouve également d’autres responsabilités dans la couche 2, notamment :
- L’adressage : la couche 2 offre à chaque appareil une adresse matérielle, ou adresse MAC, afin que chaque appareil puisse être identifié au sein du réseau local (eh non, ce terme n’est pas propre à Ethernet !)
- La détection et correction d’erreurs : des phénomènes physiques peuvent corrompre la donnée lorsqu’elle est transmise à la couche 1, la couche 2 permet donc de corriger ces erreurs, par exemple avec des mécanismes de checksum ou de CRC.
Couche 3 : Réseau (Network)
Si la couche 2 définissait ce qu’était un réseau local et ses limites, la couche 3 adresse l’interconnexion de ces différents réseaux, et donc l’envoi de messages à une machine distante, c’est-à-dire en dehors du réseau local (inter-networking : internet !).
Parmi les rôles remplis par la couche 3, on trouve notamment :
- L’adressage logique : la couche 2 fournit déjà une adresse physique, mais celle-ci n’est utile qu’au sein du réseau local, et n’est pas très utile si elle appartient à l’un des milliards d’autres réseaux existants. Il est donc nécessaire d’offrir une autre adresse, qui contient en elle l’identifiant du réseau local à laquelle elle appartient.
- Le routage : à partir du moment où un paquet réseau n’appartient pas au réseau local mais à un réseau distant, que ce soit en source ou en destination, il est nécessaire d’établir des règles pour déterminer comment traiter un paquet reçu d’une source externe, ou comment et à quel réseau distant envoyer un paquet non local.
- La fragmentation des paquets : les messages à envoyer passent logiquement par les couche 2 et 1, mais certains protocoles de couche 2 présentent une limite sur la taille des messages pouvant circuler (la fameuse MTU : Maximum Transmission Unit, par exemple une trame Ethernet de base fait au plus 1500 octets). Si le message des couches supérieures est plus grand que cette limite, la couche 3 a pour responsabilité de le fragmenter et de l’envoyer en plusieurs paquets, qui seront reconstitués sur la couche 3 du destinataire.
Une petite analogie pour rendre tout ça moins flou : imaginons un service postal dans une petite ville. Comme le nombre d’habitants est limité, le facteur connaît tout le monde, et chaque lettre peut ainsi être simplement adressée au nom du destinataire (Madame Michu, Papy Mougeot…). Soudain, il est nécessaire d’envoyer un message à Hubert Rauquessore, qui habite un des nombreux autres villages. Sans plus d’information, il est impossible pour le facteur de résoudre le problème : il ne sait même pas dans quel village se trouve Hubert ! Il lui faut donc une forme d’identification supplémentaire, par exemple dans notre exemple un code postal. Ainsi, sachant que Hubert habite à Clochemerle, notre facteur peut simplement envoyer le courrier au service postal de cette ville, et c’est leur facteur local, connaissant ce bon vieux Hubert, qui pourra lui donner sa lettre.
Couche 4 : Transport
La couche de transport est la dernière des couches basses. À l’aide des trois couches précédentes, nous pouvons désormais adresser une machine distante, mais un certain nombre de problématiques reste : comment faire communiquer plusieurs programmes entre deux machines sans interférence mutuelle ? Et, si l’on le désire, comment assurer la bonne réception des paquets envoyés et leur intégrité ? La couche 4 répond à ces questions.
Pour répondre à la première question, nous devons (encore !) ajouter une nouvelle forme d’adressage : après l’adresse matérielle qui identifiait une machine de manière absolue au sein d’un réseau local, après l’adresse logicielle qui identifiait une machine sur un inter-réseau, nous ajoutons une adresse permettant d’identifier un processus au sein d’une machine, car il est évident qu’un poste ne peut pas se contenter d’établir une seule connexion à la fois ! Pour reprendre l’analogie du facteur, on peut considérer que cette adresse représente un numéro d’appartement au sein d’un immeuble. Sans trop de surprise, et sans trop nous avancer sur les articles futurs, c’est bien évidemment la notion de ports TCP et UDP qui reprennent ce rôle au sein du modèle TCP/IP.
Les autres responsabilités sont quelque peu optionnelles, mais se trouvent dans la couche 4 si on désire les implémenter :
- La couche de transport peut offrir une garantie de bonne réception des messages envoyés à travers un mécanisme d’accusés de réception, et proposer une retransmission des paquets le cas échéant.
- Elle permet aussi l’établissement et la clôture d’une connexion, c’est-à-dire plutôt que de paquets indépendants et autonomes (qu’on appelle alors datagrammes), des paquets faisant partie d’une série de communication plus large, garantissant également leur réception dans le bon ordre.
Couche 5 et 6 : Session et Présentation
Nous attaquons désormais les trois couches hautes du modèle, et soyons honnêtes : il n’est pas particulièrement pertinent de s’attarder sur les deux suivantes plus que nécessaire, ces couches n’ayant jamais été véritablement implémentées, et les suites de protocoles dominants ne comportent pas vraiment d’équivalents. Nous nous contenterons donc d’un léger paragraphe pour chacune d’entre elle, par simple curiosité :
La couche 5 est la couche de session, et comme son nom l’indique, elle permet l’établissement de sessions, c’est-à-dire de liens logiques persistants entre deux processus, pour échanger sur une longue période. En pratique, cela correspond à fournir aux programmes une API pour créer, configurer et terminer des sessions. Dans une certaine mesure, on pourrait concevoir en plissant des yeux que l’interface des sockets BSD se situe sur la couche 5, bien que ce ne soit pas un protocole à proprement parler.
La couche 6, quant à elle, est la couche de présentation, et s’occupe des problématiques de traduction (à comprendre dans un sens d’encodages différents), de compression et de chiffrement de session. Elle permet donc à différentes machines avec des modes de représentation divers de communiquer de manière uniforme sur le réseau.
Couche 7 : Application
Enfin, nous pouvons nous attaquer à la dernière couche du modèle OSI : la couche d’application. Sans surprise, cette couche contient tous les protocoles « métier », tels que HTTP, FTP, DNS, et ainsi de suite. Il est important de ne pas entendre « application » dans le sens d’un programme s’exécutant comme une machine, mais bien du protocole réseau utilisé par ce programme. C’est par exemple la différence entre un navigateur comme Firefox, et le protocole HTTP qu’il utilise pour demander des pages.
Il n’est pas non plus nécessaire de trop s’attarder sur cette couche : le domaine applicatif est un monde à part entière, sujet à ses propres standards et ses besoins “métier”. Néanmoins, nous aurons l’occasion d’étudier certains protocoles de couche 7 qui ont pour objectif de configurer et d’agir sur le fonctionnement du réseau en lui-même, comme DNS et DHCP.
Un peu de terminologie
Sans surprise, le vocabulaire de l’ingénieur réseau est un mélange de termes standards et de jargons, dont l’utilisation abusive peut facilement noyer le lecteur non averti. Défrichons un peu.
Pour commencer, le modèle OSI définit des noms spécifiques au types de message selon la couche dans laquelle ils se situent, résumés dans le schéma suivant :
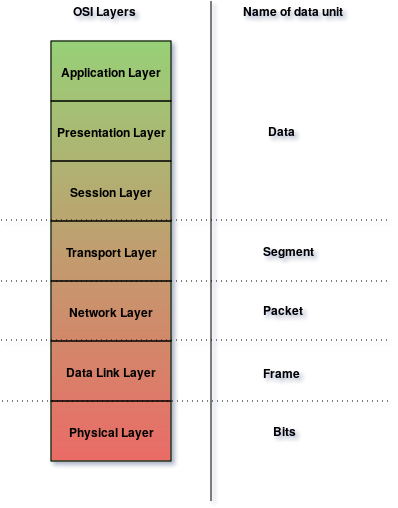
Couches OSI et types de messages
Un réseau local au sens de la couche 2 est communément appelé un “link”, ce qui donne beaucoup plus de sens à certains protocoles (une adresse “link local” est une adresse qui n’a de sens qu’au sein d’un link donné, et le protocole LLTD, Link Layer Topology Discovery, est le protocole utilisé par les versions récentes de Windows pour leur schéma du réseau local, parce qu’utiliser LLDP qui est l’équivalent standard c’était trop compliqué pour eux il faut croire). On trouve également assez souvent le terme de “segment L2”, mais attention à ne pas confondre avec le segment au sens de message situé à la couche 4 !
Un adaptateur réseau (le machin dans lequel vous branchez votre câble RJ45 sur votre machine, ou bien votre carte wifi) est souvent abrégé en NIC, pour Network Interface Card.
Enfin, un problème situé en couche 8 est un subtil euphémisme pour mettre en cause la compétence de l’utilisateur qui se plaint à la DSI de sa boîte que “ça marche pas” (et qui a à tous les coups appliqué une dose de “maintenance percussive”, je vous laisse imaginer à quoi ça ressemble).
Le modèle TCP/IP
Le modèle TCP/IP et ses protocoles associés, plus formellement appelée Internet Protocol Suite, ou plus rarement le modèle DoD (Department of Defense, les commanditaires originaux du modèle), est aujourd’hui omniprésent, et sans aucun doute ses protocoles ont été utilisés à l’instant pour que votre ordinateur récupère l’article que vous êtes en train de lire. Revenons rapidement sur son historique.
Historique
Après le déploiement d’ARPANET en 1969, la DARPA continue ses travaux de recherches, dans le but d’établir le nouveau protocole qui évoluera dessus. Il s’agit d’offrir un protocole permettant l’interconnexion de différents réseaux et l’envoi de messages à travers ceux-ci. À noter que dans le cadre de ce projet, la connectivité au sein d’un réseau local (l’équivalent de la couche 2 du modèle OSI) est considérée comme déjà acquise.
À ce titre, elle met en œuvre deux chercheurs, Robert Khan et Vint Cerf, dont l’objectif est de construire un protocole pour lequel la fiabilité de la connexion soit la responsabilité des hôtes à chaque bout de la communication, plutôt que le réseau en lui-même. En 1974, Khan et Cerf publient la première version de ce protocole, le Transmission Control Program (TCP).
À l’origine, ce protocole s’occupait à la fois du routage des paquets et de la transmission en elle-même (si vous avez bien suivi, il s’agit là des couches 3 et 4 du modèle OSI), les développeurs étant plutôt méfiants vis-à-vis des modélisations à base de couche, mais la croissance du protocole amena de nombreux chercheurs à suggérer une division en deux couches, et donc deux protocoles distincts. On peut notamment lire l’intervention de Jon Postel, l’éditeur des RFC, qui commence la rédaction de la RFC IEN #23 par les mots suivants :
We are screwing up in our design of internet protocols by violating the principle of layering. Specifically we are trying to use TCP to do two things: serve as a host level end to end protocol, and to serve as an internet packaging and routing protocol.
Le protocole est donc découpé en deux, la partie s’occupant de la transmission des paquets est renommée en Transmission Control Protocol, alors que celle ayant pour charge le routage des paquets est nommée Internet Protocol.
Architecture
Ainsi, même si les considérations initiales envers un design par couche étaient plutôt froides, le concept est tout de même repris bien qu’avec un certain nombre de précautions, notamment pour se prévenir de la rigidité que pourrait engendrer une telle découpe arbitraire. Un des premiers articles décrivant l’architecture du modèle est la RFC 11224, qui propose un modèle en 4 couches, visualisées ci-après :
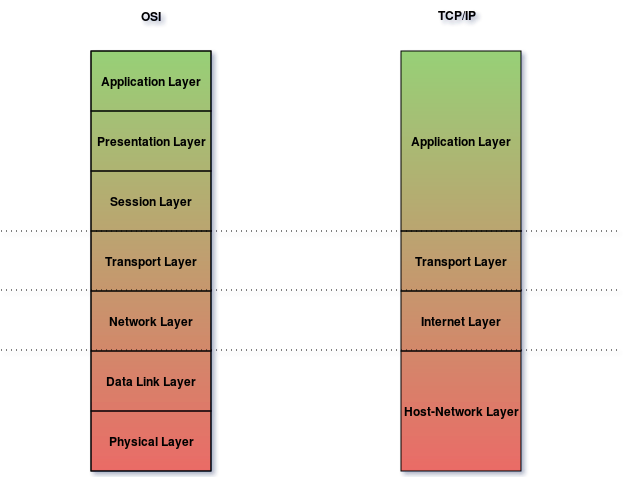
Comparaison du modèle TCP/IP avec le modèle OSI
Host-Network Layer
Également appelé Link Layer (le terme de link pouvant être employé pour décrire un réseau local), cette couche n’a pas vocation à être fournie par TCP/IP, mais est un pré-requis pour le déploiement du modèle, qui part du principe que le réseau existant permet déjà d’offrir une connectivité locale. Cette couche englobe donc les couches 1 et 2 du modèle OSI.
De plus, le choix de ne pas imposer un protocole de couche 2 en particulier permet de les faire cohabiter, et donc de faire communiquer des réseaux ayant chacun une connectivité différente, que ce soit ARPANET ou Ethernet, qui est le protocole de couche 2 le plus répandu aujourd’hui, voire… le pigeon voyageur à en croire la RFC 1149 (RFC de poisson d’avril bien sur, mais qui est souvent utilisée pour démontrer que techniquement, le protocole IP peut être déployé indépendamment du support sous-jacent).
Néanmoins, le modèle propose des interfaces et des protocoles pour permettre la liaison entre la couche de liaison et la couche internet, typiquement pour traduire une adresse IP en adresse MAC. De nos jours par exemple, c’est le protocole ARP qui occupe ce rôle, et permet de traduire une adresse IPv4 en adresse MAC Ethernet.
Internet Layer
Similairement à la couche 3 du modèle OSI, cette couche s’occupe d’une part de l’adressage et l’identification d’une machine via les adresses IP, d’autre part du routage de paquet, afin de les envoyer à leur réseau de destination.
Le protocole IP, qui existe sur cette couche, sera le sujet d’un article dédié.
Transport Layer
Sans trop de surprises, cette couche s’occupe des mêmes problématiques que la couche 4 du modèle OSI, et introduit la notion de ports pour représenter le multiplexing par processus.
Le protocole TCP, ainsi que son petit frère UDP, seront le sujet d’un article dédié.
Application Layer
La couche applicative regroupe toutes les couches supérieures du modèle OSI, et englobe tous les protocoles « métier » qui seront déployés au dessus de la pile TCP/IP. Tout comme pour OSI, il n’y a pas grand chose de très intéressant du point de vue du réseau à en dire, si ce n’est que les couches dédiées à la session et la présentation sont définitivement enterrées.
Aujourd’hui : le modèle hybride
Une limitation du modèle TCP/IP est qu’il se permet de mettre dans un gros sac tout ce qui se cache sur ses couches inférieures, et expose donc une vision un peu trop abstraite de la réalité du travail d’un ingénieur réseau. Aussi, il est assez courant pour un ingénieur de visualiser un modèle hybride, reprenant les points essentiels des deux précédents.
De plus, nous pouvons désormais nous permettre, par métonymie, de substituer le nom des couches par celui des protocoles majeurs qu’on retrouve dessus:

Modèle hybride
Notons que par abus de langage, et par référence aux bons jours d’OSI, la couche applicative est appelée la couche 7, bien que techniquement elle ne soit que la 5ème dans ce modèle.
Comme vous l’avez compris, l’objectif des articles suivants sera de s’attarder sur les couches 2, 3 et 4 de ce modèle à travers l’étude approfondie de leurs protocoles respectifs, à savoir Ethernet, IP et TCP.
Pas de crainte, les prochains articles contiendront beaucoup moins d’histoire, et beaucoup plus de technique !
Les limites de la modélisation par couche
Modéliser la problématique réseau en couche est pratique et utile, mais il faut malgré tout faire attention à ne pas sombrer dans les effets pervers d’une modélisation excessive. En particulier, deux croyances sont à évacuer au plus vite, sous peine d’être victime du syndrome de la vache sphérique5 :
Croire que toutes les problématiques sont traitées par le modèle
Un contre-exemple rapide : quid de la sécurité ? On ne trouve pas de couche dédiée à cet aspect, d’autant plus qu’il est transverse et ne prend pas la même forme selon la couche étudiée ! Ainsi, il faut différencier la sécurité couche 2 (avec 802.1X par exemple), de celle de la couche 3 (IPSec) ou encore celle des couches supérieures (TLS)…
Croire que tout protocole rentre sagement dans une case
Attention à la “pulsion classificatrice” ! Il est tentant d’avoir le réflexe, à la découverte d’un nouveau protocole, de chercher immédiatement à le situer dans la couche adaptée pour déterminer la portée de ses responsabilités. Malheureusement, certains protocoles sont récalcitrants, et résisteront à cette analyse. On aura notamment l’occasion d’étudier ARP (Address Resolution Protocol), qui s’occupe de traduire une adresse IP en une adresse MAC, et se situe forcément quelque part entre les couches 2 et 3, sans vraiment appartenir à une suite de protocole particulière.
Conclusion
À travers ce premier article, nous avons donc pu survoler le cadre théorique dans lequel les différents protocoles réseaux évoluent, ainsi que le contexte historique qui a amené à la modélisation actuelle. Mais la partie ne fait que commencer, et nous n’avons pour l’instant qu’étudié le paysage sans regarder les acteurs vivant dedans. Ce sera chose faite dès l’article suivant, qui mettra la lumière sur le protocole Ethernet et son histoire.
Références et bibliographie
W. Richard Stevens. 1994. TCP/IP Illustrated, Volume 1: The Protocols
Kozierok, Charles. 2005. TCP/Ip Guide: A Comprehensive, Illustrated Internet Protocols Reference. No Starch Press.
Russel, Andrew. 2014. Open Standards and the Digital Age: History, Ideology and Networks. Cambridge University Press. ↩︎
Russel, Andrew, 2013, OSI: The internet that wasn’t. ↩︎
Braden, Robert. 1989. RFC 1122: Requirements for Internet Hosts – Communication Layers. ↩︎
Postel, Jon. 1979. RFC Ien #2: Comments on Internet Protocol and Tcp. ↩︎
Wikipedia, Spherical cow ↩︎